기사입력 2024.10.09 04:54


UNIST(총장 박종래) 전기전자공학과 변영재 교수팀은 이동 중인 차량에 끊김이 없이 전력을 공급하는 ’무선 전력 공급 트랙‘을 개발하며, 전선으로 구성된 넓고 강한 자기장을 형성해 고가 자석인 강자성체 없이도 앞뒤 좌우 유연한 차량 주행이 가능할 것으로 기대가 모아진다.
2024-08-19 오전 10:31:52by 배종인 기자

과학기술정보통신부(장관 이종호)는 소프트웨어(SW) 분야 우수한 기초·원천기술을 보유한 대학 연구실을 지원하는 2024년도 SW스타랩 사업의 선정 결과 인공지능에서는 △서울대 주한별 교수 △KAIST 김준모 교수, 빅데이터에서는 KAIST 신기정 교수 △고려대 이상근 교수, 클라우드에서는 KAIST 유민수 교수 △고려대 김중헌 교수, 알고리즘에서는 △포항공대 오은진 교수 △포항공대 배경민 교수, 응용SW에서는 △KAIST 노준용 교수 △UNIST 임치현 교수 연구실이 선정됐다.
2024-08-19 오후 4:12:38by 배종인 기자

UNIST 에너지화학공학과 서관용 교수팀은 유리와 같이 무색 투명한 특성을 유지하면서도 높은 효율을 지닌 새로운 형태의 투명 태양전지와 모듈을 선보였다. 스마트폰 적용시 스마트폰 화면에서 배터리를 직접 충전할 수 있는 기술로 향후 상용화시 친환경 에너지를 선도할 것으로 기대된다.
2024-08-20 오전 8:11:18by 배종인 기자

UNIST(총장 박종래)는 에너지화학공학과 안광진 교수팀·서울대 한정우 교수팀이 한국에너지기술연구원과 협력해 성능이 뛰어난 로듐 기반 촉매를 개발했다. 이 촉매는 부생가스에 포함된 올레핀을 고부가가치 알데하이드로 효율적으로 전환한다. 올레핀은 이중결합을 갖는 불포화 탄화수소 화합물로, 파라핀과 함께 화학산업에서 중요한 원료로 사용된다.
2024-08-23 오전 8:47:49by 배종인 기자
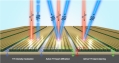
UNIST(총장 박종래) 전기전자공학과 이종원 교수팀은 전기로 제3 고조파를 조절할 수 있는 ‘비선형 광학 메타표면’을 개발했다. 외부에서 가해지는 신호나 자극에 따라 빛의 특성이 변해 복잡한 광학 신호를 조절하는 기술이다.
2024-08-26 오전 11:22:35by 배종인 기자

UNIST(총장 박종래) 화학과 최원영 교수팀이 차세대 탄소중립 소재로 주목받는 금속-유기 골격체를 더욱 효율적으로 발굴할 수 있는 설계 전략을 개발했다.
2024-09-10 오전 9:50:35by 배종인 기자

UNIST(총장 박종래) 에너지화학공학과 안광진 교수팀과 LG화학 탄소중립연구 TFT는 이산화탄소를 활용해 지속 가능한 항공유(SAF) 생산에 적합한 이소파라핀 생성 촉매를 개발했다.
2024-09-12 오전 10:25:28by 배종인 기자
[열린보도원칙] 당 매체는 독자와 취재원 등 뉴스이용자의 권리 보장을 위해 반론이나 정정보도, 추후보도를 요청할 수 있는 창구를 열어두고 있음을 알려드립니다.
고충처리인 장은성 070-4699-5321 , news@e4ds.com





