
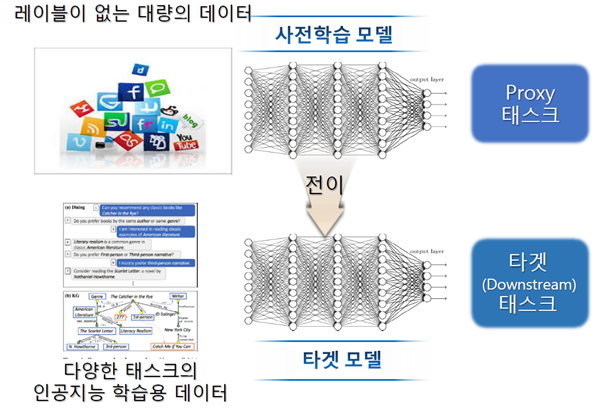

IBM이 인간의 관용어나 구어적 표현까지 식별·분석할 수 있는 AI 신기술을 공개했다. 왓슨 API로 제공되는 기술을 통해 기업은 구어적 표현이 포함된 언어 데이터까지 분석할 수 있게 되었을 뿐만 아니라 데이터에 담긴 지식을 활용하는 방법에 대한 통찰력까지 얻을 수 있다.
2020-03-12 08:35:28by 최인영 기자
.jpg)
SK텔레콤이 국립국어원과 업무 협약을 체결하고, 국립국어원의 언어 정보를 활용해 한국어에 최적화된 차세대 AI 언어 모델을 개발하기로 했다. 차세대 AI 한국어 모델은 오픈AI 연구소가 개발한 영어 기반 GPT-3 언어 모델와 유사한 성능의 한국어 범용 언어 모델(GLM)이다. 언어 관련 문제 풀이, 글짓기, 번역, 주어진 문장에 따라 간단한 코딩을 수행하는 등 사람 수준의 GPT-3 기능을 한국어에도 구현할 수 있다.
2021-04-08 08:15:28by 이수민 기자

현대자동차그룹이 한국지능정보사회진흥원(NIA, National Information Society Agency)과 손잡고 자동차 분야 인공지능(AI, Artificial Intelligence) 학습용 데이터를 공유하며, 국내 자동차 SW 발전 가속화 및 경쟁력 강화에 나선다.
2021-04-09 08:31:43by 배종인 기자