
노타가 모빌린트와 AI 최적화 기술 공급 계약을 체결했다. 모빌린트는 자사 NPU 제품군에 노타의 AI 모델 최적화 플랫폼 ‘넷츠프레소’를 도입해 하드웨어와 모델 최적화 환경을 함께 제공할 계획이다. 양사는 MLA100, MLA400 기반 제품과 노타의 비전 AI 솔루션 NVA를 연계해 산업안전, 지능형 교통체계, 스마트시티, 보안관제 등 엣지 영상 AI 분야에서 협력을 추진한다.
2026-05-07 09:19:38by 명세환 기자
.jpg)
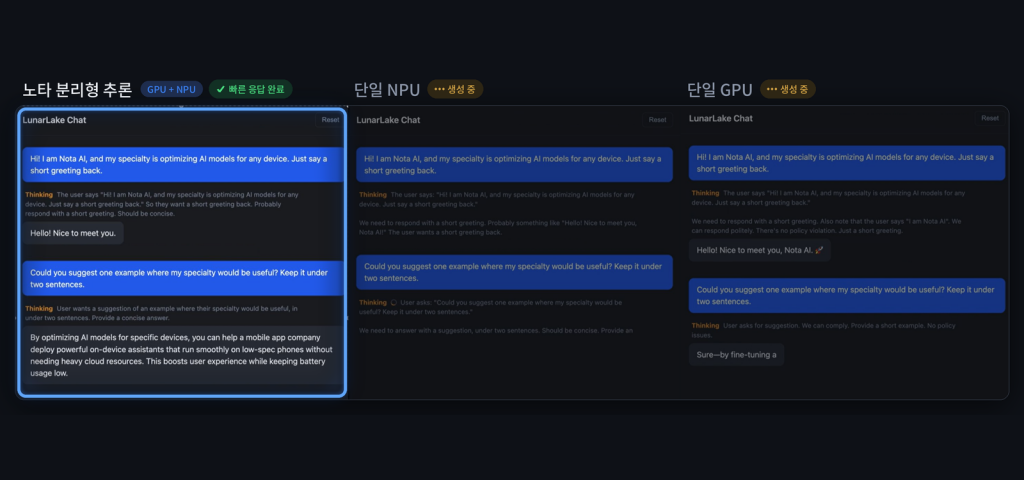
노타의 영상 관제 솔루션 ‘NVA’가 ‘2026 올해의 엣지 AI·비전 제품상’ 대규모 멀티모달 모델 부문 수상작으로 선정됐다. NVA는 비전 언어 모델을 활용해 영상 속 객체와 상황을 분석하고, 실시간 설명과 사고 요약, 안전 보고서 생성 기능을 제공한다. 단일 엣지 장비에서 최대 32개 영상 채널을 분석하며, F1 스코어 85% 이상의 성능을 구현했다. 노타는 교통, 산업안전, 스마트시티 등 영상 AI 수요가 있는 분야로 적용 범위를 넓힐 계획이다.
2026-05-12 11:18:51by 명세환 기자

AI 경량화·최적화 기술 기업 노타가 2026년 1분기 연결 기준 매출 35억8,000만원을 기록하며, 사업 확대 흐름을 이어갔다. 수주잔고 증가와 적용 영역 확장이 향후 실적에 영향을 미칠 것으로 보인다.
2026-05-18 11:33:08by 배종인 기자
노타가 직무발명제도 운영 우수사례 공모전에서 최우수상인 지식재산처장 표창을 받았다. 이번 수상은 임직원의 발명 성과를 체계적으로 보상하고, 이를 특허 자산과 사업 경쟁력으로 연결해 온 운영 방식이 평가받은 결과다. 노타는 2026년 5월 기준 AI 모델 최적화·경량화와 영상 AI 분야를 중심으로 국내외 특허 227건을 확보했다.
2026-05-28 10:32:41by 배종인 기자
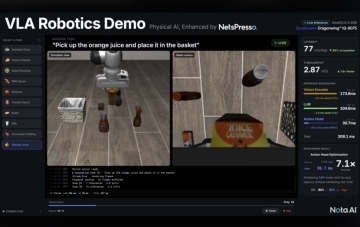
노타가 퀄컴 엣지 AI 디바이스 ‘드래곤윙(Dragonwing) IQ-9075’ 환경에서 비전·언어·행동 통합 모델(VLA)을 최적화해 실행 속도를 개선했다고 밝혔다. 해당 모델은 ‘스몰VLA(SmolVLA) 0.45B’로, 실시간 동작 생성을 포함한 피지컬 AI 환경을 고려해 구현됐다.
2026-05-29 15:11:24by 배종인 기자
노타가 엔비디아의 영상 검색·요약 기술(VSS)을 적용한 영상관제 솔루션 NVA의 현장 적용 사례를 공개했다. 대전지방국토관리청 교통관제 시스템과 코오롱인더스트리 김천2공장에 적용된 NVA는 CCTV 영상에서 사고, 위험 상황 등을 분석하고 관제자가 필요한 정보를 자연어로 검색·요약할 수 있도록 지원한다.
2026-06-01 11:06:03by 명세환 기자

노타가 엔비디아 아시아태평양 파트너 행사에서 피지컬 AI 확산에 따른 엣지 AI 최적화 기술의 필요성을 공유했다. AI가 도시와 산업 현장 등 물리 공간에서 실시간으로 작동하기 위해서는 클라우드 의존도를 낮추고 현장 가까이에서 데이터를 처리하는 기술이 중요하다는 취지다. 노타는 온디바이스 AI 최적화 기술을 기반으로 스마트시티, 교통, 산업 현장 등에서 작동하는 AI 에이전트의 적용 방향을 설명했다.
2026-06-02 14:09:20by 명세환 기자
